Introduction
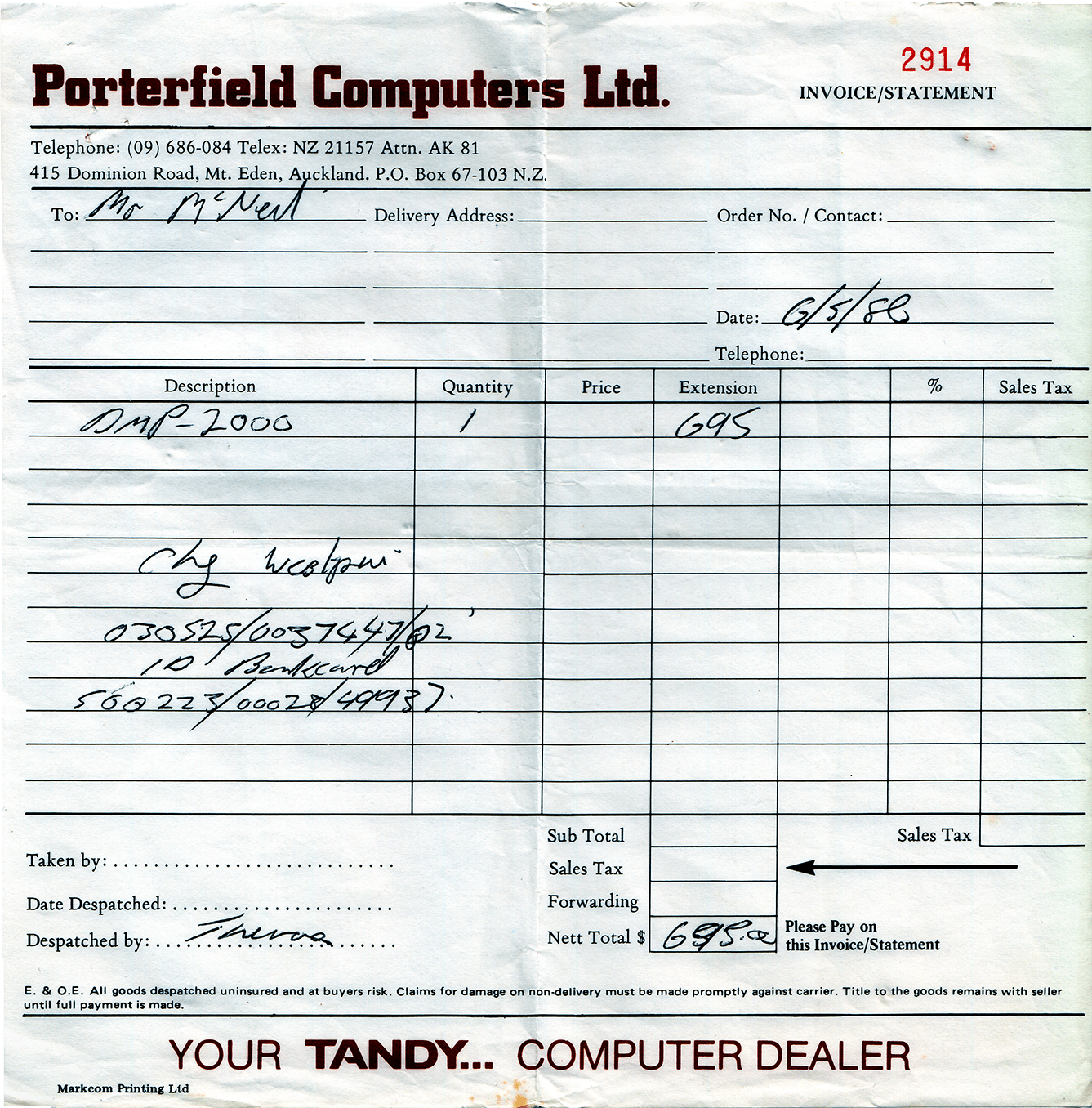
Almost 32 years ago (on 1986-04-30), after much begging, my parents bought an Amstrad CPC6128 with an Amstrad GT65 Green Screen Monitor from Porterfield Computers Ltd in Wellington. Together with a word processor (Tasword 6128), the Pitman Typing Tutor, and two 3" Floppy Discs (narrower than the much more common 3.5" floppy discs), this all cost NZ$1500.65 -- in 1986 dollars (over NZ$3500 in 2017 dollars, according to the Reserve Bank Inflation Calculator; also packing slip from Grandstand). An Amstrad DMP-2000 printer came a week later, for NZ$695.00 (again 1986 dollars; over NZ$1600 in 2017 dollars), and about a year later an Amstrad FD1 3" external second drive for NZ$299.00 (in 1987; around NZ$700 in 2017 dollars).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
For a middle class family in New Zealand in the 1980s that was quite a bit of money. It changed my life forever. While it was originally a "family" computer, it fairly rapidly became my computer, because I was the one using it all the time.
I learnt to touch type on the Amstrad CPC, learnt to program on the Amstrad CPC, and even learnt about computer hardware from expanding the Amstrad CPC6128. For about 6-7 years the Amstrad CPC6128 was my "everyday" computer -- a long time for any computer, and an especially long time when the personal computer market was changing so rapidly. Over the years I added two Dk'tronics 256KiB Memory Expansion modules (for a total of 576KiB -- bank switched on a 8-bit microprocessor! -- as the first 64KiB of the expansion overlaid the second 64KiB on the Amstrad CPC6128), an Amstrad Serial Interface, an external 5.25" floppy drive and even a MFM hard drive via a SCSI controller board and a home built SCSI adapter.
{kind=link}
The Amstrad Serial Interface (and the poor software with it, that could not even keep up with 2400bps let alone display IBM PC extended characters and formatting) led to me write EwenTerm, the largest Z80 Assembler program that I wrote (and one I used daily for several years to keep up with multiple BBSes) -- which also changed my life forever). EwenTerm's source was also the basis of Glenn Wilton's BBS Terminal, developed by another Wellington, New Zealand local. Glenn took the source I wrote and polished it into a more useful communication program, including file transfers (EwenTerm development basically stopped once I had reliable "ANSI terminal" functionality working).
(For several years I had "EwenTerm" online with a URL that suggested it was "ansiterm" -- a URL I had chosen because the program did not really have a name and was written to be an ANSI terminal. More recently this has led to some confusion, as there was an AnsiTerm by Paul Martin, which was well reviewed in Amstrad Computer User Issue 4 on pages 48 and 49, but seems to be a different program, independently developed at about the same time. Unfortunately I appear to have added to the confusion by responding to an email from Kevin Thacker saying "I would like to contact Ewen McNeill concerning his program for the Amstrad CPC called 'Ansiterm'." with the link to my software, resulting in an AnsiTerm page on the CPC that links to both my EwenTerm source and the review about Paul Martin's AnsiTerm. I have emailed Kevin Thacker again to try to get this corrected, and it appears to be corrected there too now.)
{kind=link}
{kind=link}
The hard drive leads us to our story today. Around 1989 I bought a second hand ST-506 interface MFM hard drive to add to my Amstrad CPC6128. It was 10MB, and even second hand cost a few hundred dollars. The Amstrad CPC6128 did not have a hard drive interface (although various third parties created some later), but I eventually found out about SCSI to MFM Controller cards and ordered one of those second hand (from the USA). Then to link the Amstrad CPC6128 to the SCSI 1 interface I built a simple adapter card that plugged into the Amstrad CPC6128 expansion interface. On a 4MHz Z80 CPU reaching even the 3.5MB/s to 5MB/s of SCSI 1 was a challenge, but due to the buffering in the SCSI to MFM controller, it worked although probably not as fast as the controller and drive were capable of working.
I used the hard drive on the Amstrad CPC6128, under CP/M Plus along with the two Dk'tronics RAM expansion modules, and CP/M BIOS extensions written by Bevan Arps (then of Christchurch, New Zealand) for a couple of years, from around 1991 to 1993. Eventually the call of IBM PC Compatible hardware became too strong, and I put together the first of many PC Compatible machines -- from second hand parts -- which gradually supplanted my Amstrad CPC6128 as my "daily compute".
Floppy disc backup
In the middle of 1993 I made a backup of my Amstrad CPC6128 hard drive, onto floppy disks, and then on 1994-03-31 (date I wrote on the box!) the Amstrad CPC was packed away in boxes. I got those boxes out about 14 years ago -- in 2004 -- and made an attempt at transferring some of the floppy disks onto a PC, but between issues with reading the floppy disks (due to age), and difficulty reading the contents of the floppy disks (due to CP/M file formats) that project gradually got overtaken by events and sat on the hard drive of one of my Linux machines for a decade.
Several recent events encouraged me to take another look, including randomly being given a second Amstrad CPC6128 at a conference earlier this year, as well as being contacted by Kevin Thacker about AnsiTerm, and Jason Scott's repeated encouragement to Close the Air Gap and get things online (someone "closing the air gap" gave us the Walnut Creek CP/M CDROM from 1994 back again -- I bought a copy of it in 1994 when it came out, but somewhere in the last decade I put it "somewhere safe" and cannot remember where that is... :-( ).
Fortunately the backup of my Amstrad CPC6128 hard drive was one of the sets of disks where I managed to copy all the backup disks that I could find into disk images back in 2004, so the "air gap" had already been closed -- they just had not been unpacked. (Unfortunately I could find only discs 1/11 to 11/15, suggesting that 4 discs are missing -- but I no longer remember if there ended up being 11 discs total or 15 discs total. It appears maybe the disks were re-used from an earlier backup, which maybe did require 15 disks.)
Unfortunately, the backups were on 5.25" double sided floppy discs in an extended disc format for Nigdos, developed in New Zealand, with CP/M Plus support released on WACCI PD Disc 7. There is also a NigDos 2.24 ROM image available, but that has no documentation. It seemed like extracting the data from the backup disks would be non-trivial.
It turned out that WACCI PD Disk 7 can be
downloaded
(Side A CRC A2CDE9B5; Side B CRC 12FEA3FC; two 180KiB disk
images). The disk image checksums can be checked with crc32:
ewen@linux:~$ crc32 *
a2cde9b5 WACCI-PD-Disc-07-Side-A.dsk
12fea3fc WACCI-PD-Disc-07-Side-B.dsk
ewen@linux:~$
which match the ones listed on the download page.)
So I thought it was worth reading those disks to see if I could find out any more information about the disk format used.
Side quest: Accessing Amstrad CPC .dsk files
Which means that we get to find out (again!) how to read files
from Amstrad CPC .dsk images on Linux. There seem to be a few options:
Kevin Thacker's cpcxfs and dskinfo, also with source available (but apparently written with MS-DOS/Windows as the primary platform; the main tool can be built under Linux from source). Based on cpcfs, which I assume has fewer features as the README contains a redirect to
cpcxfsright at the top.libdsk optionally via cpmtools support of
libdsk(included with acpmtoolscompile option). Whilecpmtoolshas been packaged in Debian Linux of years, adding this extra support requires compiling from source: cpmtools source and libdsk source. There are some utilities included withlibdskwhich may be sufficient for some purposes (eg, disk image file conversion) in some situations.iDSK written by Sid (in French; Google Translation), with source available.
SamDisk by Simon Owen for which there is source on GitHub for a development version, released under the MIT license.
As it turns out the .dsk images downloaded above were created
with SamDisk, and appear to be unreadable with anything other
than SamDisk. So in order to extract them we need to use SamDisk
to convert them. (I did try converting them with dskconv from
libdsk, but it also was unable to read them :-( I am unclear
how SamDisk extended the extended disk format, but the extension
appears to confuse other tools...).
However SamDisk works with full disk images, rather than the file
system within the disk image, so it cannot extract the files from
the disk image. Which means that we need to use SamDisk to convert
the disk image to something that we can read with another tool. The
output formats of SamDisk
are relatively limited -- it will write .dsk files, but it appears
only in its Extended format, which is what we already have.
After conversion to a .raw file, we can then use cpmtools to
read files out of the disk image.
SamDisk
To build SamDisk:
git clone git clone https://github.com/simonowen/samdisk
cd samdisk
sudo apt-get install cmake
cmake -DCMAKE_BUILD_TARGET=Release .
make
which after a while, will give us a samdisk binary, that can be
installed with:
sudo make install
(The build takes a couple of minutes as SamDisk is written in C++
which always compiles relatively slowly on Linux.)
After installaton, we can test that it recognises the disk images with:
samdisk dir WACCI-PD-Disc-07-Side-A.dsk
and then convert them to .raw disk images (ie, no sector headers)
which cpmtools can read with:
samdisk copy WACCI-PD-Disc-07-Side-A.dsk WACCI-PD-Disc-07-Side-A.raw
samdisk copy WACCI-PD-Disc-07-Side-B.dsk WACCI-PD-Disc-07-Side-B.raw
There is a complaint on these files that "source missing 27 sectors
from 43/1/9/512 regular format", but this appears to be due to the
.dsk headers indicating there are 43 tracks, but the actual data
contains only the standard 40 tracks, so I ignored it.
cpmtools
cpmtools has been packaged in Debian Linux for years, so once we have
a .raw image file, we can just use the packaged version directly and
specify the implicit disk format of the sectors. To do this:
sudo apt-get install cpmtools
cpmls -f cpcdata WACCI-PD-Disc-07-Side-A.raw
cpmls -f cpcdata WACCI-PD-Disc-07-Side-B.raw
(mkdir side-a && cd side-a && cpmcp -f cpcdata ../WACCI-PD-Disc-07-Side-A.raw 0:* .)
(mkdir side-b && cd side-b && cpmcp -f cpcdata ../WACCI-PD-Disc-07-Side-B.raw 0:* .)
Other tools
Ultimately SamDisk and cpmtools was the only combination that worked
with the *.dsk files that I had downloaded (imaged by SamDisk). But I
did try several of the other tools listed above before determining this,
and record how to build them, so I am keeping those details below for
future reference. They do appear to work with other .dsk images,
presumably those extracted earlier or with different tools.
dskinfo
To build dskinfo:
wget http://cpctech.cpc-live.com/download/dskinfo.zip
unzip dskinfo.zip
cd dskinfo
mv makefile Makefile
rm -f dskinfo *.o
make
which builds a single dskinfo binary in the source directory (and
the archive ships with a pre-built version, built in 2011).
dskinfo usage is simple:
dskinfo disk_image.dsk
dskinfo outputs verbose (!) information about the sectors in the
.dsk file, but also confirms that it is an "Extended CPCEMU style"
.dsk file image. However the tool just outputs metadata; it does
not actually read the data out of the disk.
cpcxfs
Encouraged by that I built cpcxfs:
wget http://cpctech.cpc-live.com/download/cpcxfs.zip
unzip cpcxfs.zip
cd cpcxfs/src
mv makefile.lnx Makefile
make clean
make
(There are lots of warnings, mostly about const safeness and signedness
safeness, but it does build.)
cpcxfs usage is either via the command line or interactive (if run
without a command it goes into interactive mode). To use from
the command line:
List files on disk:
cpcxfs DISK_IMAGE.dsk -dPut a file on the disk:
cpcxfs DISK_IMAGE.dsk -g ...Get a file from the disk:
cpcxfs DISK_IMAGE.dsk -p ...Put multiple files on the disk:
cpcxfs DISK_IMAGE.dsk -mg ...Get multiple files from the disk:
cpcxfs DISK_IMAGE.dsk -mp ...
(-mg and -mp take CP/M style wildcards, eg, *.*; -g and -p take
single filenames.)
Unfortunately (a) cpcxfs also does not support the "Extended
CPCEMU style" .dsk format, at least as used in the WACCI PD Disk
7 .dsk files created by SamDisk that I downloaded, and (b) it
will complain it cannot open the disk image, even for a directory
listing, if the file is write protected which seems unfortunate.
The lack of support for (all? some?) Extended CPCEMU style disk
images is particularly unfortunate as Kevin Thacker (who released
cpcxfs) is one of the creators of the Amstrad CPCEMU Extended Disk
Format.
That format information helped me confirm that the WACCI PD .dsk
images I had downloaded were created with
SamDisk under Microsoft Windows,
because "SAMdisk130107" appears in the .dsk image header. Given
that these disks were public domain disks the use of the "Extended"
.dsk format appears to be accidental (the "Extended" .dsk format
was intended for copy protected disks), but one needs to work with
what one can find. And unfortunately those .dsk images appear
to be the only one available online. (SamDisk supports a lot
of formats.)
iDSK
To build iDSK:
wget http://sid.cpc.free.fr/iDSK.0.13-src.tgz
tar -xzf iDSK.0.13-src.tgz
cd iDSK.0.13/iDSK
aclocal
automake
autoconf
./configure --prefix=/usr/local
make clean # the downloaded archive includes .o files
make
Then the resulting binary is in src/iDSK which you could copy somewhere
on your PATH manually, or use sudo make install (which appears
to contain a lot of shell magic to do the same thing).
iDSK is written in French, including French help, but the commands
are fairly obvious from context:
List files on disk:
iDSK disk_image.dsk -lImport file:
iDSK -i file.bin -t 1 -s disk_image.dskExport file:
iDSK -g file.bas -s disk_image.dsk
where the "type" (-t) is 0 for ASCII and 1 for binary.
Unfortunately iDSK did not support the Amstrad/Spectrum Extended .DSK data
files used by the WACCI PD Disk files I downloaded so it was not useful
to me here, and since the output is in French (which I do not read very
well) I am more likely to use other tools.
libdsk
To build libdsk:
wget http://www.seasip.info/Unix/LibDsk/libdsk-1.5.8.tar.gz
tar -xzf libdsk-1.5.8.tar.gz
cd libdsk-1.5.8
aclocal
automake --add-missing
autoconf
./configure --prefix=/usr/local
make
That then gives a library, and a series of tools:
dskconv: disk image conversion (new in 1.5.x)dskdump: sector level copy from disk/image to another disk/imagedskform: format a floppy disk/imagedskid: identify a floppy disk/imagedskscan: scan a floppy disk for sectorsdsktrans: transfer from one disk/image to another disk/imagedskutil: a sector editor
which can be installed into /usr/local/ by running:
sudo make install
To actually run them on modern Linux it is necessary to ensure they can find the shared library:
echo /usr/local/lib | sudo tee /etc/ld.so.conf.d/usr-local-lib.conf
sudo ldconfig
After that, in theory we can use dskconv (from the libdsk 1.5.x series)
to convert from the Extended .dsk image file to a standard .dsk
image file. There is no man page for dskconv yet, so the help
is just output by running the raw command:
ewen@linux:/var/tmp/amstrad$ dskconv
Syntax:
dskconv {options} in-image out-image
Options are:
-itype <type> type of input disc image
-otype <type> type of output disc image
'dskconv -types' lists valid types.
-format Force a specified format name
'dskconv -formats' lists valid formats.
Default in-image type is autodetect.
Default out-image type is LDBS.
eg: dskconv diag800b._01 diag800b.ldbs
dskconv -otype raw diag800b._01 diag800b.ufi
ewen@linux:/var/tmp/amstrad$
The supported image file types are:
ewen@linux:/var/tmp/amstrad$ dskconv -types
Disk image types supported:
remote : Remote LibDsk instance
rcpmfs : Reverse CP/MFS driver
floppy : Linux floppy driver
dsk : CPCEMU .DSK driver
edsk : Extended .DSK driver
apridisk : APRIDISK file driver
copyqm : CopyQM file driver
tele : TeleDisk file driver
ldbs : LibDsk block store
qrst : Quick Release Sector Transfer
imd : IMD file driver
ydsk : YAZE YDSK driver
raw : Raw file driver (alternate sides)
rawoo : Raw file driver (out and out)
rawob : Raw file driver (out and back)
myz80 : MYZ80 hard drive driver
simh : SIMH disc image driver
nanowasp : NanoWasp image file driver
logical : Raw file logical sector order
jv3 : JV3 file driver
cfi : CFI file driver
ewen@linux:/var/tmp/amstrad$
And we could in theory convert a disk image with:
mkdir edsk dsk
# Put source files in edsk
dskconv -otype dsk edsk/WACCI-PD-Disc-07-Side-A.dsk dsk/WACCI-PD-Disc-07-Side-A.dsk
but unfortunately libdsk also reports the disk image is unreadable :-(
At this point I looked harder at SamDisk and discovered that there was
source for a development version on GitHub, so built that and used SamDisk
and cpmtools to extract the files (as described above). It appears that
SamDisk (and maybe some emulators) support an Extended Extended version
of the .dsk format, and relatively few other tools support that specific
format.
DiskImager
More searching turned up
DiskImager, which
looks like it should be able to visualise the extended .dsk files,
and is written using the Lazarus FreePascal
system (a Delphi-compatible free IDE).
It does not support file extraction directly, but it appears it can
convert between Extended and Standard .dsk file formats. Because
of the need to install a custom development environment I decided
to skip past this one for now (but it does look very useful for
preservation work). Because I have not tried it I do not know if
it supports the same Extended .dsk format variations as SamDisk.
dsktools
Other searching turned up
dsktools originally
written by Andreas Micklei),
and originally released on
SourceForge and
Berlios (now gone). The most recent version of dsktools is on
GitHub
To build dsktools:
git clone https://github.com/cpcitor/dsktools
cd dsktools/dsktools
make clean # Ignore errors of files not existing
make
(Due to the way that the source was rescued from
Berlios, both the
git repository and the directory are called dsktools, so there
is effectively a second level in the git repository.)
This gives two tools dskread and dskwrite, which can be installed in
/usr/local/bin with:
sudo make install
Usage is dskread and dskwrite, but they will only read from /dev/fd0
and write to /dev/fd0, so they are not useful for working with already
imaged .dsk files :-(
Back to the main quest: reading the NigDos backups
Nigdos disk format
As mentioned above, I previously imaged the NigDos backup floppies
on Linux with a simple C program (readnigdos --
readnigdos.c,
and
Makefile)
that read raw sectors using the Linux floppy driver and output the
raw sector data to a file, in the order I believed was in use.
"format.doc" and "extdisc.doc" from the WACCI-PD-Disc-07-Side-B
extracted above (with SamDisk and cpmtools) give information on the
NigDos formats:
The Extra Formats you can create are as follows:
Name: Usable Space:
V Vendor Format 169K
D Data Format 178K
P PCW A Drive Format 173K
B Nigdos Big Format 208K
T Nigdos Two Side Format 416K
C CPM Big Format 416K
L CPM Large Format 716K
H CPM Huge Format 816K
and that reminded me that the most likely format was the "Nigdos Big Format". But it provided no information on the precise layout of the disk format.
From my earlier guesses when I wrote readnigdos (14 years ago!), I
believe the Nigdos Big Format is:
512 byte sectors (
size_ind=2in CP/M terminology)10 sectors per track, numbered
0x91to0x9a(following the Amstrad CPC convention of using the sector number as a hint of the format)42 tracks per side (numbered 0 through 41)
2 sides (0 and 1)
Tracks ordered "out then out", ie all of side 0 is used and then all of side 1 is used, ie:
Track 0, Side 0 Track 1, Side 0 Track 2, Side 0 ... Track 41, Side 0 Track 0, Side 1 Track 1, Side 1 Track 2, Side 1 ... Track 41, Side 1
I actually tried asking Bevan Arps if he remembered the track layout, but after 25 years he was guessing as much as I was. Bevan's thought was that it was probably alternating sides -- ie Track 0, Side 0 then Track 0, Side 1, to reduce seeking, and that probably would have been my first guess too for the same reason. However it turns out that both were supported -- "NigDos 420K Double Sided" was "all side 0 then all side 1" (in order, as above), with sectors 0x91 to 0x9a, and "CPM 420K Double Sided" was "interleaved side 0 and side 1" as we first guessed, with sectors 0xa1 to 0xaa (see end of blog post for some more detail).
Having actually installed cpmtools (above), it turned out that
one of its disk definitions (in /etc/cpmtools/diskdefs) included
the Nigdos format:
diskdef nigdos
seclen 512
# NigDos double sided disk format, 42 tracks * 2 sides
tracks 84
sectrk 10
blocksize 2048
maxdir 128
skew 1
boottrk 0
# this format wastes half of the directory entry
logicalextents 1
os 3
end
which seemed to match what I had detected (512 bytes * 10 sectors/track
* 42 tracks/side * 2 sides = 430080 bytes; 512 bytes * 10 sectors/track
* 84 tracks = 430080). That means that assuming the tracks are in the
right order in the disk image file cpmtools should be able to extract
the files out of the backups. (And I would assume for both "NigDos 420K"
and "CPM 420K" assuming the tracks off the floppy disk end up in the
image file in logical order rather than physical order.)
I believe the comment that "this format wastes half of the directory entry" relates to using 16-bit block numbers, rather than the 8-bit block numbers which would be sufficient for a 420KiB floppy disk using 2KiB blocks. This appears to have happened for backwards compatibility, and compatibility with the larger formats (eg, 716KiB and 816KiB above) which had over 256 * 2 KiB blocks and thus did need the 16-bit block numbers. In practice there were sufficiently many directory entires, and sufficiently little space, that running out of directory entries was not a problem in practice; it is just an odd data recovery quirk to be aware of later.
Reading the backup disk images
According to the notes from the disk labels (which fortunately I also transcribed back in 2004) the backups contained:
User 0: disks 1-5
User 1: disks 5-9
User 2: disk 9
User 3: disk 9-10
User 4: disk 10-11 (and implicitly 12/13, but I could not find them back in 2004 when I imaged the backup floppy discs)
This tends to suggest that some files will be missing from the backup :-( (At least unless I eventually find the missing floppies, and they are still readable 25 years later.) However the last disk is not full (and still contains "deleted" data) so possibly these were old backup disks that were overwritten but the labels never updated to indicate that fewer disks were required.
Anyway I could list the files on the backup disks with:
for DISK_IMAGE in *.nigdos; do
cpmls -f nigdos -F "${DISK_IMAGE}"
done
which gave sensible output, although only about 400 files in total. However 11 disks at 420KiB each works out to about 4.5MiB, which is roughly the portion of the hard drive I made available (because some information from the hard drive tables needed to be held in RAM, and holding more in RAM took up too much of the Amstrad CPC RAM space -- so I only ever made 5MiB available). Certainly the disk images seemed to all have 370-400KiB used.
I believe that cpmls will by default list the files in all users areas.
That, plus scanning the CP/M directories in the "hexdump -C" output
suggested that all the files on the backups were in User 0 of the
floppy disks.
So I extracted all the files into a specific directory per disk with:
for DISK in $(seq -f "%02.0f" 1 11); do
(mkdir -p "${DISK}" && cd "${DISK}" &&
cpmcp -f nigdos -p ../"cpc-hd-backup-1993-06-19-disk-${DISK}-of-15.nigdos" "0:*" .)
done
and then zipped that into a more modern archive for future reference:
zip -9r cpc-hd-backup-1993-06-19.zip [01]*
Looking through the backup it appears that it is mostly CP/M programs which were the main thing I would have been likely to store on the hard drive rather than the floppy drive. But there are few other gems included in there.
It appears that the files have been extracted properly, but the only
easy way to tell is by reading text files, and looking for files stored
with checksums (.ark/.arc, .zoo, .zip, etc).
Reading .ark/.arc
files (the
original System Enhancement Associates archive format) on Linux is possible
with nomarch:
sudo apt-get install nomarch
nomarch -l ARCHIVE # List files
nomarch -t ARCHIVE # Test checksums of files in archive
Confirming the NigDos Double Sided Format (sectors 0x91 to 0x9a)
One of the gems from looking around was the source code to Bevan Arp's
format, extdisc, etc, that he had apparently sent to me in 1989.
So I sent that back to him. It seemed only fair :-)
The "extdisc" source file contained the definitions of the extra floppy disk formats:
DataFormat equ 0
Block2K equ 128
Sectors10 equ 32
Tracks8082 equ 64
NigDos equ 16
Interlace equ 4
TwoSideRev equ 8
TwoSideNorm equ 12
Reserve1Track equ 1
Reserve2Track equ 2
; Format Of Data
; byte FirstSectorNumber
; byte Flags
; word DiscSpace
[...]
; NigDos 420K Double Sided
byte &91
byte DataFormat+Sectors10+NigDos+TwoSideNorm+Block2K
word &d1
; CPM 420K Double Sided
byte &a1
byte DataFormat+Sectors10+Interlace+Block2K
word &d1
The "SetFormat" routine in that source ends up rotating the flags
values twice ("rra; rra" in Z80 assembly), and then storing them
in the Amstrad Extended Disk Parameter Block
(XDPB) as the "sidedness"
field -- which is called "SID" in the source code.
As described in the seasip.info XDPB documentation)
DEFB sidedness
;Bits 0-1: 0 => Single sided
; 1 => Double sided, flip sides
; ie track 0 is cylinder 0 head 0
; track 1 is cylinder 0 head 1
; track 2 is cylinder 1 head 0
; ...
; track n-1 is cylinder n/2 head 0
; track n is cylinder n/2 head 1
; 2 => Double sided, up and over
; ie track 0 is cylinder 0 head 0
; track 1 is cylinder 1 head 0
; track 2 is cylinder 2 head 0
; ...
; track n-2 is cylinder 2 head 1
; track n-1 is cylinder 1 head 1
; track n is cylinder 0 head 1
which means:
"4" (
Interlace) turns into "1" when rotated right twice, and so is interleaved/interlaced;"8" (
TwoSideRev) turns into "2" when rotated right twice, and so is up/over/back"12" (
TwoSideNorm) turns into "3" when rotated twice, and is specially handled in the patched "TranslateTrackin the source code, to implement "out and out", the format that I had guessed (it skips over the Interleave routine, and then skips over the "Up and Over" track number reversal logic, resulting in just "track = track - tracks_per_side").
This confirms my guesses that the disk format that I had uses all
of side 0 in order, then all of side 1 in order, which means my
readnigdos.c
implements the right logic for the sector values it is reading.
Conclusion
Overall this was a long adventure (14+ years if you count from when
the floppy disks were read in; 25+ years from when they were written),
but I appear to have successfully recovered about 4.5MB of data backed
up from my CP/M hard drive, to explore later. I have also confirmed
the format of the "NigDos 420K Two Sided" floppy disks that I created,
which gives me confidence to recover data from the other floppy disk
images I made in 2004. And I have several tools to extract files from
Amstrad CPC .dsk files produced in various eras with various tools.
Overall a very successful quest, but rather time consuming!
ETA, 2018-03-05: History of Amstrad CPC464 creation -- the first model, that led to the Amstrad CPC6128 a year or so later. (Archived Version Page 1 and Page 2)
ETA, 2018-03-11: Added date Amstrad CPC was packed away.
ETA, 2018-07-12: This blog post was mentioned on the CPC Wiki
Forum. The amstrad
tag has links to other
posts about recovering Amstrad CPC data.